
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |
- 프로그래머스
- githubactions
- 티스토리챌린지
- 스프링부트
- 메시지
- yaml-resource-bundle
- 스프링
- 파이썬
- springsecurity
- oauth2
- springsecurityoauth2client
- 백준
- 국제화
- 리프레시토큰
- 소셜로그인
- springdataredis
- 액세스토큰
- docker
- java
- 오블완
- JIRA
- 토이프로젝트
- 스프링시큐리티
- 도커
- CI/CD
- 재갱신
- 데이터베이스
- 트랜잭션
- Spring
- AWS
- Today
- Total
땃쥐네
[DataBase] 트랜잭션의 격리 수준(Isolation Level) 본문
이전 글에서 데이터베이스의 트랜잭션이 무엇인지, 트랜잭션의 4대 특성 ACID는 무엇인지 확인해봤습니다.
동시에 실행되는 트랜잭션들이 서로에게 영향을 미치지 않아야 한다는 격리성(Isolation)을 지키기 위해서, 가장 쉬운 방법은 트랜잭션을 순서대로 실행하는 방법이긴 하나, 이대로면 수 백만건의 동시요청이 들어왔을 때 순서대로 진행되느라 매우 오랜 시간이 걸리게 되는 성능 이슈가 발생한다는 것도 확인했습니다.
트랜잭션의 격리 수준을 조절함으로서 이 성능 문제를 관리할 수 있는데, 국제 표준기구인 ANSI에서는 이 '트랜잭션 격리수준'을 어떻게 정의했고 이 수준에 따라 어떤 현상들이 발생하는 지 이번 글에서 다루도록 하겠습니다.
트랜잭션의 격리 수준 완화에 따라 일어나는 현상들
1. 더티 읽기(Dirty Read)

Dirty Read는 어떤 트랜잭션 A에서, 데이터 조작이 일어나고 커밋되기 전에, A에서 더럽혀진 데이터(Dirty Data)를 다른 트랜잭션 B에서 읽게 되는 현상입니다.
이 현상은 후술할 READ UNCOMMITTED 격리 수준에서 발생합니다.
위의 그림을 보시면,
Alice의 트랜잭션에서 1번 글의 제목이 ACID로 변경되고, 롤백되기 전에
Bob의 트랜잭션에서 1번 글의 제목이 AICD로 더럽혀진 상태를 참고하게 되는 현상을 확인할 수 있습니다.
논리적으로 하나의 작업이 완전히 수행되지도 않았는데, 그 도중의 더럽혀진, 데이터 무결성에 맞지 않을 가능성이 높은 데이터를 다른 곳에서 참조하게 되는 현상이죠. 이런게 허용된다면 매우 위험한 일이 일어날 수 있습니다.
2. 반복 불가능한 읽기, 애매한 읽기(Non-Repeatable Read / Fuzzy Read)
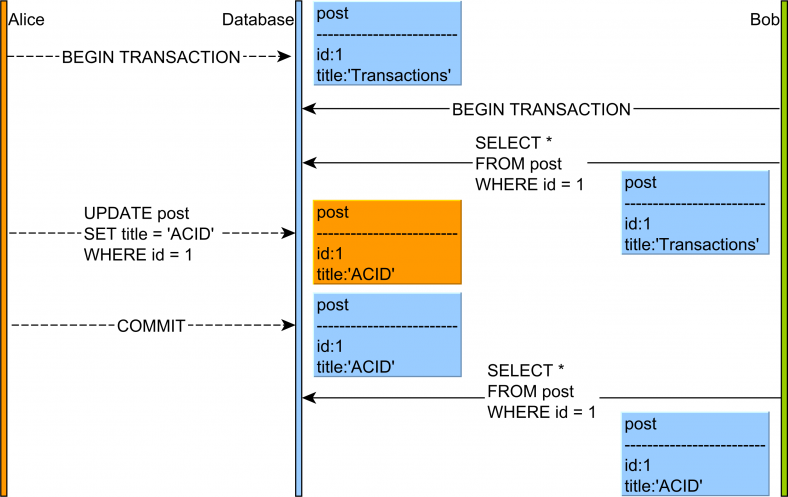
반복 불가능한 읽기(Non-Repeatable Read)는 한 트랜잭션에서 데이터를 여러번 조회할 때 1회에서 조회된 결과와 2회 이후에서 조회된 결과가 달라지는 현상입니다.
트랜잭션 B가 최초에 데이터를 조회하고, 트랜잭션 A에서 데이터가 변경, 커밋된 뒤, 다시 트랜잭션 B에서 데이터를 조회하면 처음 조회했을 때와 다른 데이터가 조회됩니다.
이 현상은 후술할 READ UNCOMMITTED, READ COMMITTED 격리 수준에서 발생합니다.
위의 그림을 보시면 Bob이 트랜잭션을 시작하고 1번 글을 확인하면 title이 'Transactions'였는데
도중에 Alice 트랜잭션에서 1번글의 제목을 'acid'로 변경하고 커밋이 일어납니다. 다시 Bob 트랜잭션에서 1번글을 조회하면 title이 'acid'로 조회됩니다. 같은 트랜잭션에서 '어떤 한 데이터'가 매번 다르게 조회된 겁니다.
3. 팬텀 읽기(Phantom Read)
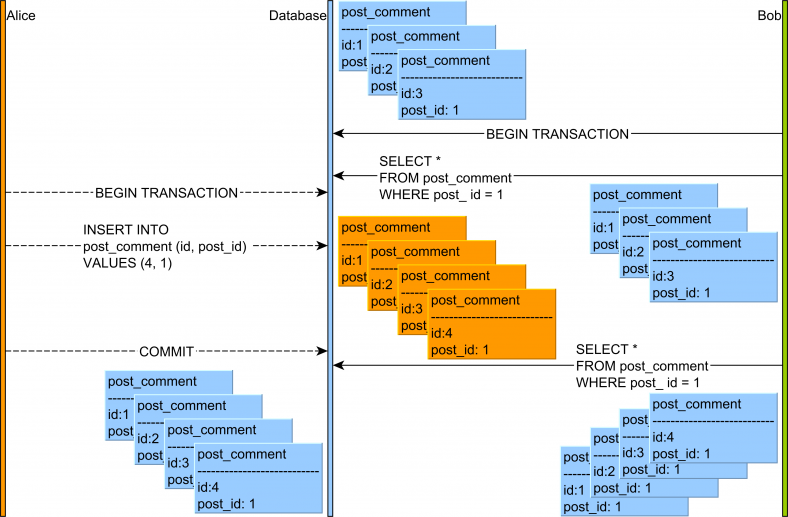
팬텀 읽기(Phantom Read)는 한 트랜잭션에서 여러번 데이터를 조회할 때 선택할 수 있는(SELECT) 데이터가 나타나거나 사라지는 현상을 칭합니다. 데이터가 나타났다 사라지는 유령(Phantom) 같다는 의미에서 이런 이름이 붙여졌습니다.
이 현상은 후술할 READ UNCOMMITTED, READ COMMITTED, REPEATABLE READ 격리 수준에서 발생합니다.
위 그림을 보시면 처음에 Bob 트랜잭션에서 데이터를 조회했을 때는 3건이였는데 alice 트랜잭션에서 데이터를 도중에 삽입되고 커밋됩니다. 커밋된 직후 다시 Bob 트랜잭션에서 데이터를 조회하면 데이터가 4개로 조회됩니다. 같은 트랜잭션에서 여러번 데이터를 조회해보니 선택된 데이터의 갯수가 달라진 겁니다.
트랜잭션 격리 수준 (Isolation Level)

국제 표준기구 ANSI에서는 트랜잭션 격리 수준들을 아래의 4가지로 정의했습니다.
- READ UNCOMMITTED
- READ COMMITTED
- REPEATABLE READ
- SERIALIZABLE
결론부터 놓고 보면 가장 느슨한 READ UNCOMMITTED, 가장 엄격한 SERIALIZABLE 수준은 실무에서 사용되지 않고 READ COMMITTED, REPEATABLE READ가 주로 사용되는데요.
이들 각각을 확인해보고 각 격리 수준에서는 어떤 현상이 발생하는 지에 대해 확인해보도록 합시다.
1. READ UNCOMMITTED(커밋되지 않은 읽기)
가장 느슨한 격리수준입니다. Dirty Read, Non-Repeatabel Read, Phantom Read가 모두 발생합니다.
이 격리 수준의 가장 큰 특징은 Dirty Read가 발생한다는 건데, 앞에서 살펴보았듯 데이터 무결성에 맞지 않는 이상한 데이터가 조회될 수 있습니다.
테이블에 락을 걸지 않을테니 속도는 매우 빠르겠지만 데이터 부정합 문제가 발생하게 되는 격리수준이므로 실무에서는 절대 사용하지 않습니다. 심지어 RDBMS 표준에서는 READ UNCOMMITTED를 트랜잭션의 격리수준으로 인정하지 않습니다.
2. READ COMMITTED(커밋된 읽기)
온라인에서 가장 많이 사용되는 격리수준입니다. Oracle DBMS에서 기본으로 이 격리 수준을 사용합니다.
위의 READ UNCOMMITTED 격리수준에서 더 제한을 걸어 Dirty Read가 일어나지 않도록 하였습니다.
하지만 Non-Repeatable Read, Phantom Read가 여전히 발생합니다.
Non-Repeatable Read가 발생하므로, 같은 트랜잭션에서 동일 데이터를 여러번 읽고 변경하는 금전적인 처리와 관련되면 문제가 발생할 여지가 있으므로 이런 상황에서는 이 격리수준을 사용하지 말고 후술할 REPEATABLE READ를 사용하시는 것이 낫습니다.
3. REPEATABLE READ(반복 가능한 읽기)
MySQL에서 기본으로 사용되는 격리수준입니다. 후술할 SERIALIZABLE 격리 수준은 사실상 사용하지 않으므로 실무적으로 사용하는 가장 높은 수준의 격리 수준이 됩니다.
위의 READ COMMITTED 격리수준에서 더 제한을 걸어 Non-Repeatable Read 가 발생하지 않게 하였으며, Phantom Read만 발생하게 됩니다.
그런데 InnoDB 엔진을 사용하는 RDBMS에서는 갭락, 넥스트 키 락 때문에 Phantom Read 현상도 발생하지 않는다고 합니다.
4. SERIALIZABLE(직렬화 가능)
가장 강력한 격리 수준입니다. 한 트랜잭션에서 읽고 쓰는 레코드를 다른 트랜잭션에서 절대 접근할 수 없도록 하는 격리 수준입니다.
동시접근 제한 자체를 막아버리니 Dirty Read, Non-Repeatable Read, Phantom Read 그 어떤 것도 당연히 발생하지 않습니다.
같은 레코드에 대해서 접근할 때 사실상 순차적으로 트랜잭션을 수행하게 될테고, 그만큼 처리 시간이 늘어나버리는 문제가 발생합니다. 동시 처리 성능이 매우 느리므로 실무에서 절대 사용하지 않습니다.
더 학습해야 할 키워드
지금까지 트랜잭션의 4가지 격리수준에 대해서 확인했습니다.
하지만 지금 확인한 것은 "각 격리수준별로 ~한 현상이 발생합니다!" 라는 결과 중심적인 학습에 불과합니다.
실제로 사용하는 데이터베이스 아키텍처는 어떤 식으로 구성되어 있고 각 격리수준별로 내부적으로는 어떤 일이 발생하는지에 대해서는 추가적으로 깊이 있는 학습이 필요합니다.
- Lock
- MVCC
- 데이터베이스 아키텍처
이 부분에 대해서는 저도 학습이 아직 덜 된 부분이기도 하고 이후 학습이 추가적으로 진행되었을 때 이 부분에 대해서 더 다뤄보도록 하겠습니다.
부족한 글을 구독해주셔서 감사합니다. 화이팅입니다!
'DataBase' 카테고리의 다른 글
| [DataBase] 관계형 모델과 집합 (0) | 2022.11.20 |
|---|---|
| [DataBase] 트랜잭션 및 트랜잭션의 4대 특성(ACID) (0) | 2022.07.31 |

