
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
- 액세스토큰
- AWS
- springsecurity
- oauth2
- 오블완
- 소셜로그인
- Spring
- 재갱신
- springsecurityoauth2client
- githubactions
- 티스토리챌린지
- JIRA
- 파이썬
- yaml-resource-bundle
- 메시지
- 스프링부트
- 토이프로젝트
- CI/CD
- docker
- java
- springdataredis
- 트랜잭션
- 데이터베이스
- 백준
- 프로그래머스
- 스프링시큐리티
- 스프링
- 리프레시토큰
- 국제화
- 도커
- Today
- Total
땃쥐네
[CS] 혼공컴운 - 2.2 0과 1로 문자를 표현하는 방법 본문
이 글은
- '강민철'님의 책 '혼자 공부하는 컴퓨터구조 + 운영체제' 책을 읽으며 학습한 내용을 정리합니다.
Intro
앞에서 학습했듯 컴퓨터는 결국 0과 1만 이해할 수 있다.
인간이 이해할 수 있는 문자들도 결국 0과 1의 비트로 변환되고, 컴퓨터는 이를 기반으로 해석해서 처리한다.
그렇다면 우리가 작성한 문자들은 어떤 형태의 비트로 변환되는 걸까? 이 규칙도 여러가지가 있는데 이를 확인해보는 것은 컴퓨터에 대한 이해를 증진시키는데 도움되기 때문에 한번쯤은 다뤄볼 필요가 있다.
1. 문자 집합, 문자 인코딩, 문자 디코딩
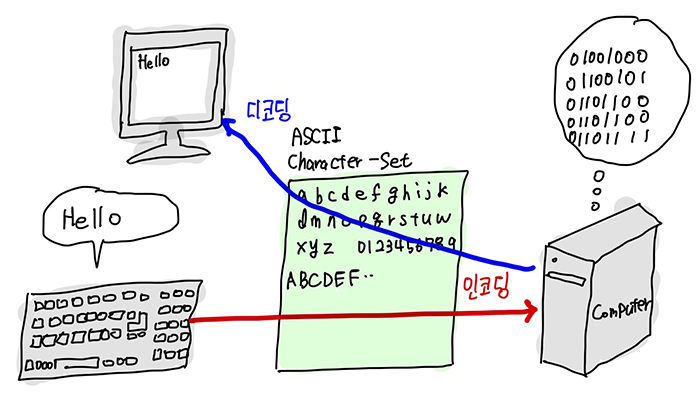
1.1 문자 집합(Character Set)
- 컴퓨터가 인식하고 표현할 수 있는 문자들의 모음
- 예) ASCII 문자집합, EUC-KR 문자 집합, CP949 문자 집합, ...
어떤 문자집합이 {a,b,c,d,e} 문자집합만을 표현할 수 있고에 대해서만 표현할 수 있고, 컴퓨터가 이 문자집합을 사용하면 컴퓨터는 a,b,c,d,e를 이해할 수 있고 f,g를 이해할 수 없다.
1.2 문자 인코딩(Character Encoding)
- 문자집합에 속한 문자를 컴퓨터가 이해할 수 있는 0과 1로 변환하는 과정 혹은 규칙
- 문자 코드(code point) : 인코딩 결과 0과 1로 이루어진 결과값
- 원래 코드 포인트가 맞는 말인데, 이 책에서는 쉬운 설명을 위해 문자 코드라고 하였음
- 예) ASCII 인코딩 : '0' -> 0b00110000
예를 들어 ASCII 문자집합은 128개의 문자들을 표현할 수 있고,
사용자가 입력한 문자열 '0'을 ASCII 방식의 인코딩을 통해 ASCII의 문자코드 0b00110000 으로 변환한다.
1.3 문자 디코딩(Character Decoding)
- 0과 1로 표현된 문자 코드를 사람이 이해할 수 있는 문자로 변환하는 과정.
- 예) ASCII 디코딩 : 0b00110101 -> 'S'
2. 아스키 코드(ASCII)
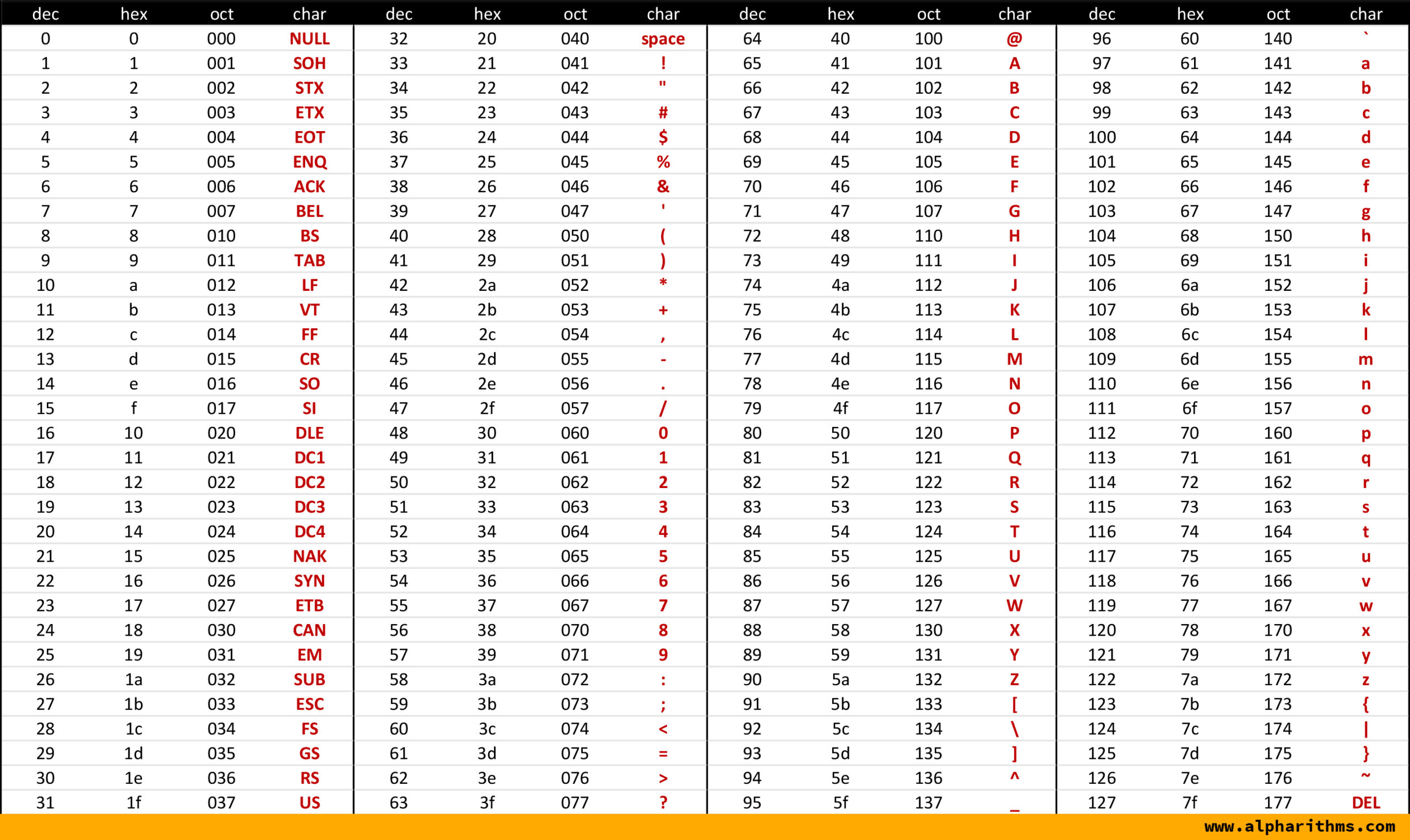
2.1 ASCII
- American Standard Code for Information Interchange
- 초창기의 문자 집합 중 하나
- 7비트로 표현할 수 있고, 아스키로 2**7 == 128개의 문자를 표현할 수 있다.
- 실제로 하나의 아스키 문자를 표현할 때는 8바이트를 사용하는데,
그 이유는 오류 검출용으로 패트리 비트(patry bit)라고 불리는 1개의 비트를 사용하기 때문이다. - 기억할 아스키 문자코드 : 48 == '0', 65 == 'A', 97 == 'a'
참고로 java의 int 타입 기준으로 0~128을 char 타입으로 형변환하면 ASCII의 규칙에 따라 형변환이 된다.
예를 들면 int로 48을 문자 '0'으로 변환할 수 있다. 알고리즘 문제를 풀 때 48, 65, 97을 외워두면 여러모로 편리하다.
2.2 한계
- 실질적으로 7비트로만 문자를 표현하기에 128개보다 많은 문자를 표현할 수 없다. 한글도 이에 해당한다.
- 더 다양한 문자 표현을 지원하기 위해, 이후 8비트의 확장 아스키도 추가됐지만 이 또한 모든 문자를 표현하기엔
턱 없이 부족하다. - 한국 등 다양한 국가에서는 자국의 언어를 0과 1로 표현할 수 있도록 고유 문자집합, 인코딩 방식을 사용했다.
3. EUC-KR, CP949
3.1 한글 인코딩 방식
- 완성형 인코딩 : 완전한 하나의 글자에 고유한 코드를 부여하는 인코딩 방식
- 예) '강' == 11101010 10110000 10010101
- 조합형 인코딩 : 초성, 중성, 종성 각각을 위한 비트열을 할당하고 이들의 조합으로 하나의 글자코드를 완성시키는 인코딩 방식
- 예) '강' == ㄱ ㅏ ㅇ == 0010 + 0011 + 0001 00011 = 0010 0011 0001 00011
3.2 EUC-KR
- KS X 1001, KS X 1003 이라는 문자 집합을 기반으로 하는 완성형 인코딩 방식
- 초성, 중성, 종성이 모두 결합된 한글 단어에 2바이트 크기의 코드를 부여함
- 한 글자를 표현하려면 2byte, 16개의 비트가 필요하다.
3.3 EUC-KR 방식의 한계
- 2350개의 한글단어를 표현할 수 있는데, ASCII보다 표현 가능한 문자의 종류는 다양해졌지만 모든 한글 조합을 표현할 수 있을 정도로 많은 양은 아니다.
- '뷁', '쀓', '믜' 같은 글자는 EUC-KR로 표현할 수 없다.
3.4 CP949
- 마이크로소프트에서 개발한 EUC-KR의 확장 버전
- EUC-KR로 표현할 수 없는 더욱 다양한 문자를 표현할 수 있다.
- 하지만 이 마저도, 모든 한글을 표현하기엔 넉넉한 양이 아니다.
4) 유니코드와 UTF-8
4.1 유니코드
- 여러 국가의 문자 집합, 인코딩 방식을 하나로 통일한 문자 집합.
- 각 국가별로, 사용하는 문자집합/인코딩 방식이 달라서 언어별로 인코딩 방식을 모두 알아야하고 변환해야한다.
이러한 수고를 덜기 위해 2~4바이트 공간에 넉넉하게 문자를 할당하고자 등장하였다. - 유니코드를 기반으로 여러가지 인코딩 방식이 존재하는데, 그 중 최근 주로 사용되는 인코딩 방식은 UTF-8이다.
4.2 UTF-8
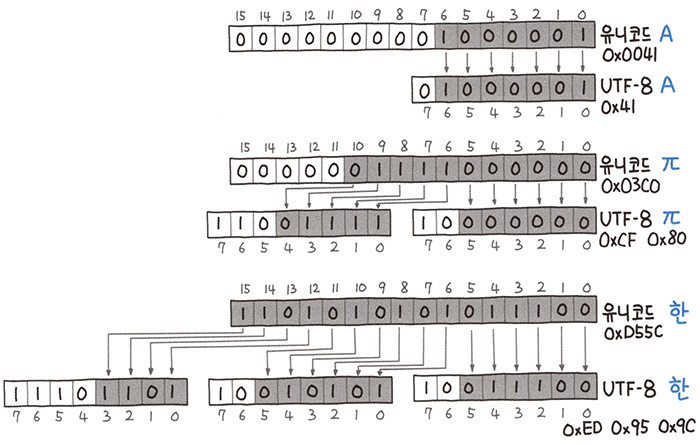
- 유니코드 자체는 1바이트로 표현이 가능한 영문자도, 2바이트 이상의 공간을 차지하기에 메모리 낭비가 심하다.
이런 문제를 해결하고자 등장한 가변 길이 문자열 인코딩 방식이 UTF-8 인코딩 방식이다. - 유니코드 값에 따라 가변 길이의 코드로 변환하여 불필요한 공간 나비를 절약할 수 있다.
- 첫 바이트의 맨 앞 비트를 확인하여 문자 전체의 바이트를 결정할 수 있다.
- 0으로 시작하면 1바이트, 10으로 시작하면 중간 바이트, 110으로 시작하면 2바이트, 1110으로 시작하면 3바이트
요즘은 사실상 UTF-8 방식이 문자 인코딩의 표준이므로 웬만하면 어떤 프로그램을 작성할 때 UTF-8 인코딩으로 작성하고, git으로 커밋할 때도 UTF-8로 인코딩해서 커밋하자. 특히 IDE를 통해 프로그래밍할 때 Windows를 사용하면 보통 기본적으로 MS949 방식으로 인코딩 되는 경우가 많은데 이렇게 되면 UTF-8로 설정된 IDE에서 열어보면 소스코드의 한글 주석 등이 깨지는 일이 자주 발생한다. git과 같은 버전관리 도구를 통해 소스코드를 저장하기 전에, 파일 인코딩이 UTF-8인지 확인하는 습관을 가지도록 하자...
'CS > Computer Structure' 카테고리의 다른 글
| [CS] 혼공컴운 - 3.2 명령어의 구조 (0) | 2023.01.15 |
|---|---|
| [CS] 혼공컴운 - 3.1 소스 코드와 명령어 (2) | 2023.01.13 |
| [CS] 혼공컴운 - 2.1 0과 1로 숫자를 표현하는 방법 (0) | 2022.12.18 |
| [CS] 혼공컴운 - 1.2 컴퓨터 구조의 큰 그림 (0) | 2022.12.18 |
| [CS] 혼공컴운 - 1.1 컴퓨터 구조를 알아야 하는 이유 (0) | 2022.12.18 |



